
Introduction
Cloudian turns information into insight with a hyperscale data fabric that lets enterprise customers in data-intensive markets store, find, and protect data across the organization and around the globe. Cloudian data management solutions bring cloud technology and economics right to your data center with uncompromising data durability, intuitive management tools, and the industry’s most compatible S3 API.
Capacity-intensive workloads demand more from your storage. You need scalable and cost-effective solutions which accommodate different formats. And you need content to be instantly available and easy to find to keep up with time-pressured schedules. Whether in media and entertainment, life sciences, big data, or video surveillance, or for use cases such as data protection or archival storage, Cloudian HyperStore delivers a storage environment that grows effortlessly from terabytes to exabytes.
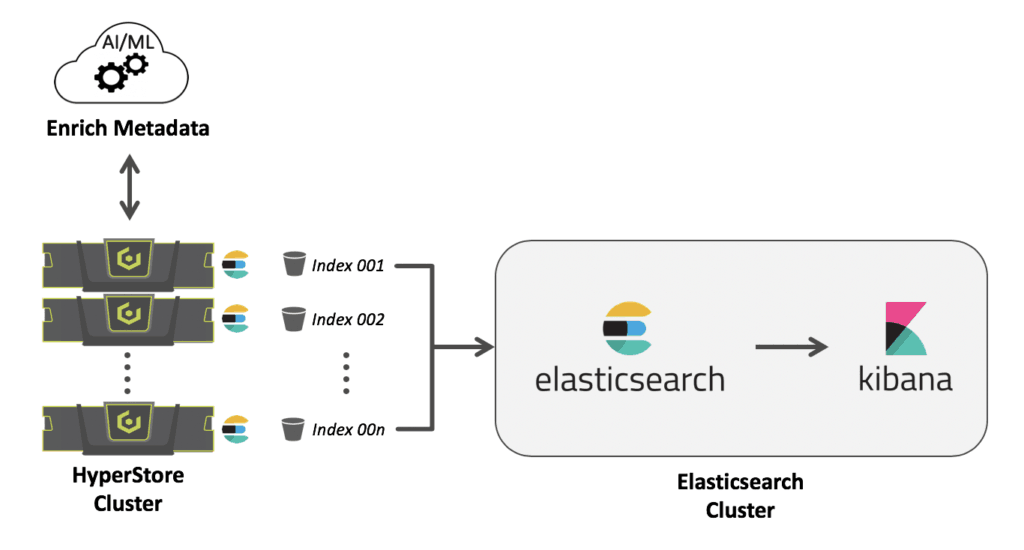
As your storage grows, the challenge of finding a needle in that haystack (the specific data you need to access) grows with it. HyperStore, by virtue of being an object storage solution, solves this problem in two key ways. First, it allows you to store system metadata and user-defined metadata along with your assets. Second, it allows you to index your metadata to search and analyze your assets with its Elasticsearch integration. Elasticsearch is an open source, real-time, distributed search and analytics engine built on top of Apache Lucene, a full-text search engine library.
To demonstrate this capability, I have uploaded ~2,500 TED videos to my HyperStore cluster. In the subsequent sections, you will learn how you can use HyperStore to analyze such assets and extract more value out of them.

Enriching Metadata
Metadata is defined as a set of data that describes and gives information about other data. One of the great advantages that object storage delivers over file and block storage is the ability to add user-defined metadata to each asset. Therefore, once you have uploaded your assets to your storage cluster, you would enrich the metadata of each asset with meaningful and identifiable information. You can store this information, such as scene content, sound clip descriptions, audio transcriptions, sentiment analysis, facial recognition, and brand recognition in the clip. This allows content creators to capture important attributes about the asset and then easily and rapidly search for and find that media later.
In addition to the existing file metadata and any user-defined metadata you set, you can further enrich the metadata using Artificial Intelligence (AI) applications, including on-prem applications, such as MachineBox, or cloud applications, such as Microsoft Video Indexer and Amazon Rekognition. Compared to the cloud applications, the on-prem AI applications are much faster since you are not sending your video files out to the cloud to be analyzed. It not only saves time but also the bandwidth. It is especially useful in a restricted environment when you have to store and analyze sensitive assets which, due to compliance, you cannot send over the Internet.
In the following use case, I used Microsoft Video Indexer and MachineBox to try both cloud and on-prem AI applications and exam how they enrich the user-defined metadata. Both applications return the output in the form of a json file that you can use to update the user-defined metadata.
Here’s an example of a video file analyzed using Microsoft Video Indexer. It gives you information about the faces present in the clip, audio transcription, keywords, annotations, and sentiment analysis.


Updating Metadata
One of the most critical steps in the process is the ability to update the metadata for an already existing object without rewriting the object. This has been one of the main challenges for major storage providers because of their architectural limitations. However, HyperStore, being built on native S3 architecture, allows you to update your metadata without rewriting your objects. This is much more efficient and results in huge savings in terms of time and cost. This also makes it a perfect solution for cases where you have already archived millions of your assets and are now planning to enrich them to extract more value out of them.
Moreover, in case of Amazon S3 and other storage providers, the user-defined metadata is limited to 2 KB in size. But, in HyperStore, you can increase the size of user-defined metadata based on your requirements.
If you are using boto3, which is the AWS SDK for Python, it can be done using the copy_from() method with MetadataDirective=’REPLACE’. Here’s the sample command:
s3.Object(bucket_name=<bucketname>, key=<filename>).copy_from(CopySource=<source file>, MetadataDirective=’REPLACE’, Metadata= <updated metadata>)
Indexing Metadata
After you have enriched and/or updated your metadata, you need to index it before you can use it to search your assets. HyperStore simplifies this process with a built-in Elasticsearch client which integrates with an Elasticsearch cluster. This Elasticsearch cluster could be a cluster that you already have running in your environment, or an Elasticsearch cluster that you install specifically for the purpose of integrating with HyperStore. After you have setup your Elasticsearch cluster and enabled the integration in the system, enabling metadata search is as simple as selecting a checkbox in the HyperStore CMC.


You can enable object metadata search on a per storage policy basis. In your Elasticsearch cluster, HyperStore will create an index for each bucket that uses a metadata search enabled storage policy. The indexes are created in the Elasticsearch cluster in the following format:
cloudian-<cloudianclustername>-<regionname>-<datacentername>-<bucketname>-<bucketcreationdatetime>
For each object that subsequently gets uploaded into a HyperStore bucket using that storage policy, HyperStore will retain the object metadata locally and also transmit a copy of that object metadata into your Elasticsearch cluster. This includes HyperStore system-defined object metadata and user-defined metadata. Whenever an object is updated or deleted in HyperStore, HyperStore’s Elasticsearch service automatically updates or deletes the metadata in the Elasticsearch cluster.
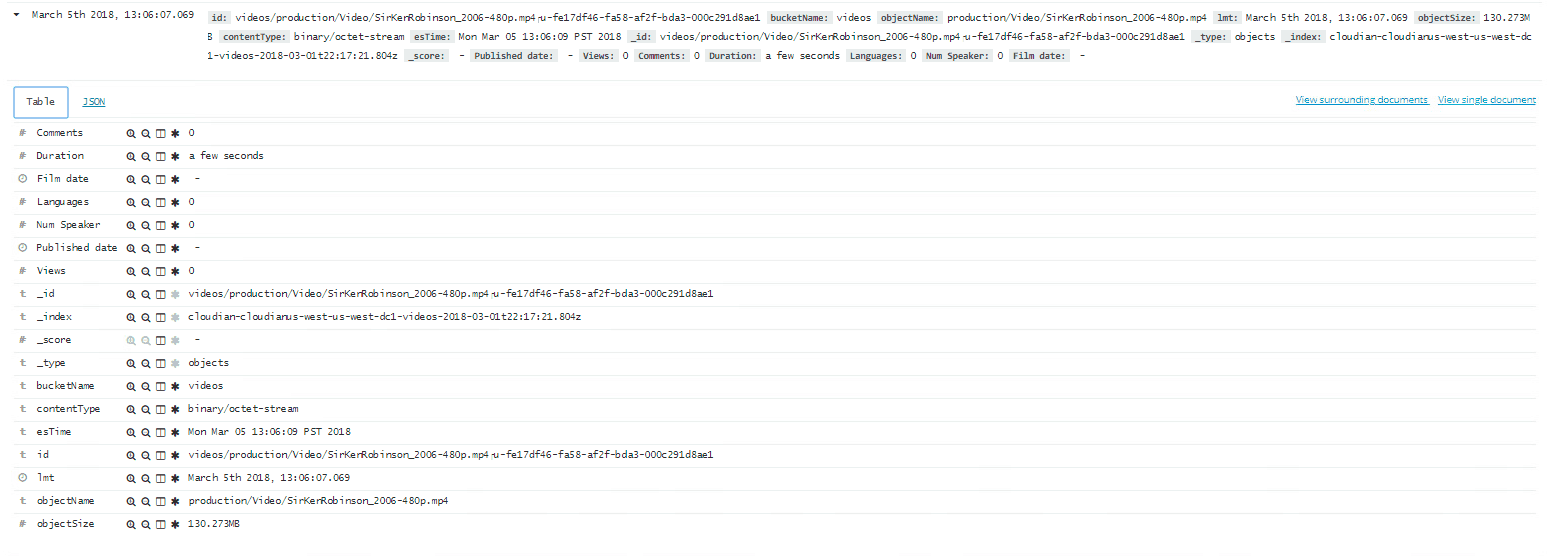
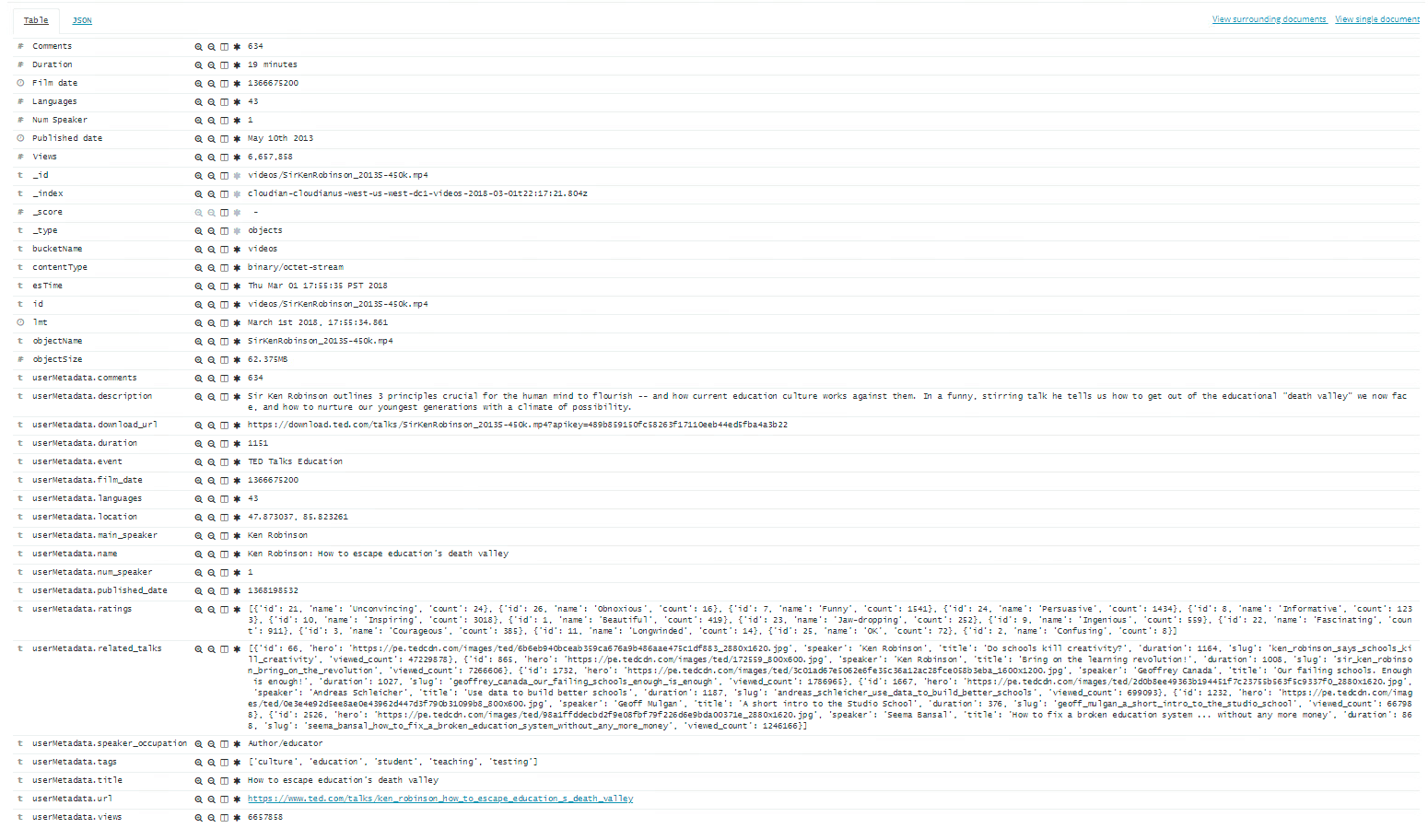
After the files have been indexed and stored in the Elasticsearch cluster, you can search through them using any of the metadata attributes. Here’s the example of an indexed file in Elasticsearch before and after the metadata enrichment.
Before

After

Visualizing Metadata
The last and final piece of the puzzle is the visualisation of your object metadata. For that you can use Kibana. Kibana is an open source analytics and visualization platform designed to work with Elasticsearch. You can use Kibana to search, view, and interact with data stored in Elasticsearch indices. It provides you with the flexibility of creating your own visualisations: histograms, line graphs, pie charts, sunbursts, and more. To take full advantage of Kibana, you might have to change the datatype of certain fields or create your own calculated fields. For that, you can use scripted fields in Kibana. Scripted fields compute data on the fly from the data in your Elasticsearch indices. However, this can be resource-intensive depending on your script and it is recommended only for experts since there is no built-in validation of a scripted field. You can either use painless or Lucene expressions for this. In this case, I decided to use Painless for creating customized calculated fields.
For this POC, I created different visualisations to analyze the TED videos uploaded in my HyperStore cluster and this is what my final dashboard looks like after putting them together. It shows you the total numbers of buckets, total number of objects, total consumed capacity, top 10 videos based on the number of views, most famous event, and the publishing patterns on a monthly basis.
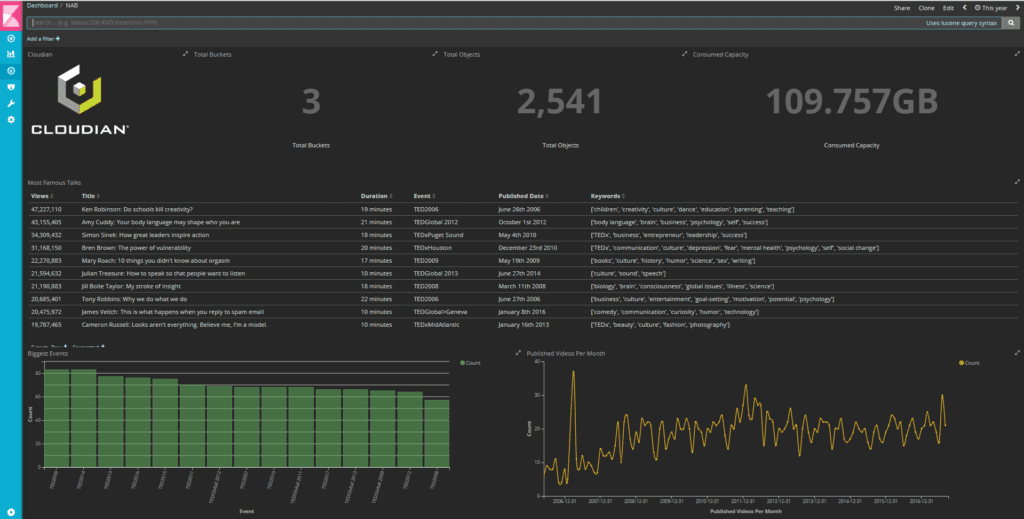

If you search for all the assets based on the keyword “Education” in the search bar, it immediately filters the results for all the visualisations.
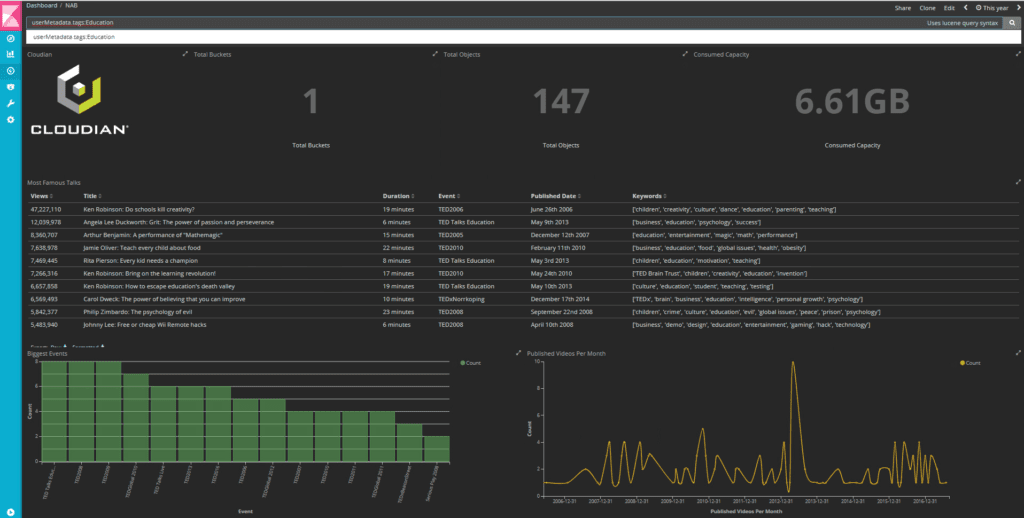

To take a step further in our analysis, if you notice in the line chart for ‘Published videos per month’, there’s a sudden spike in the year 2013 for TED talks on the topic of education.
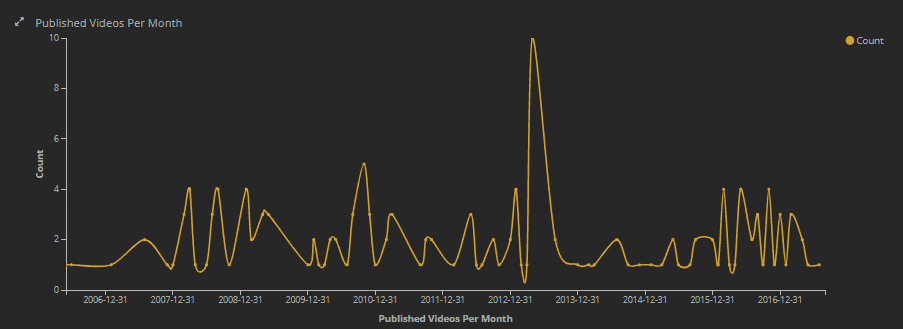

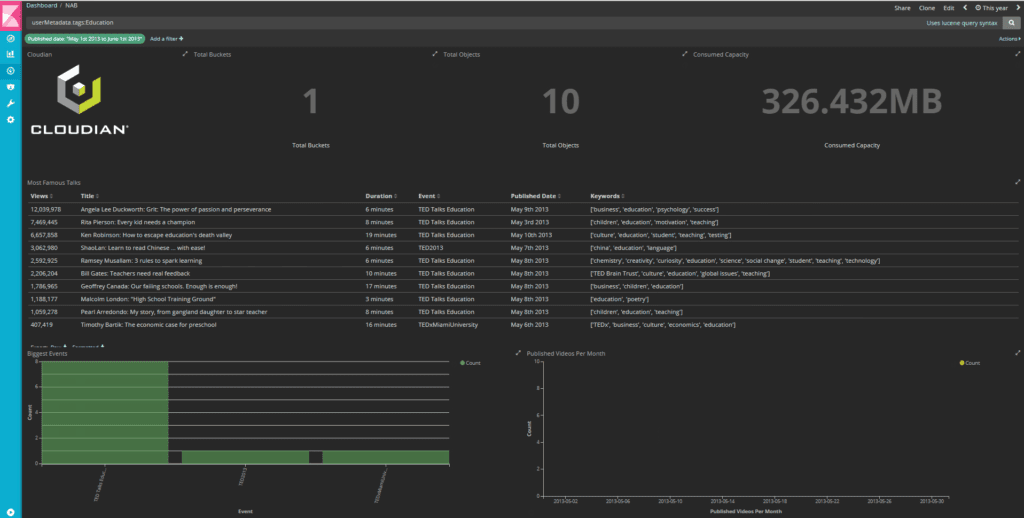
If you click on that peak, results get filtered further and you will notice in the histogram for biggest events that the spike is because of the event TED Talk Education. There were 8 TED talks in that event and they were all published in May 2013.
Conclusion
There’s a lot more you can achieve from your media assets if you have the right tools and the technology. HyperStore enables you to accomplish this by a simple yet powerful design. Apart from the above mentioned functionality, HyperStore also offers a rich set of features including quality of service controls, multi-tenancy, billing, WORM compliance, as well as the highest level of S3 API compatibility to ensure plug-and-play interoperability with S3-enabled applications.
If you are going to IBC Amsterdam this year (13 -17 September), please visit Cloudian in Hall 7 at Booth A.43 to see this demo live and in action or check out some of our partner and customer presentations in the booth (see the schedule here). You will meet with some very knowledgeable good-looking people wearing some visually bright and memorable shirts. Say hello to them and learn more about Cloudian.
Siddharth Agrawal
Sr. Technical Marketing Engineer