


View LinkedIn Profile
From Data Warehouse to Data Lakehouse: The Evolution of Data Analytics Platforms
As a data management company, Cloudian has always been interested in how organizations manage their data. A lot of attention has been paid to the WHY and HOW of data interactions, as well as WHERE data is stored. One particularly interesting combination of why, how and where is data analytics.
To date, object storage has not had a defining role in the data analytics space. Instead, organizations have mostly relied on traditional block and file storage solutions housing structured/semi-structured data. At best organizations might have placed a database backup onto an S3 object storage target, but object storage was rarely used as a primary data repository.
Today, with the business driver of building out successful data lakehouses, analytics platforms such as Greenplum, Vertica and SQL Server 2022 now support object storage data repositories via the S3 API. Many other platforms, such as Teradata, have the functionality coming soon. This means that as an S3 compatible object storage platform, Cloudian can be used to house a variety of data sets for a variety of analytics (and non-analytics) use cases!
WHY is this important?
A brief history of data warehousing and analytics will help explain.
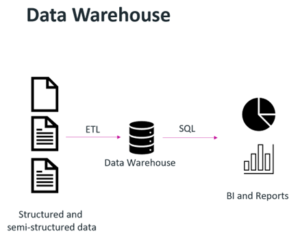
Data warehouses have existed for decades and are great for performing specific queries on structured data, such as a company billing/invoicing system. In a data warehouse, data inputs are structured; the data isn’t growing exponentially; and many frameworks/workflows exist as part of business intelligence (BI) and reporting tools. The challenge here is that as organizations have developed and evolved, so has the relationship between the organization and its data.
In the mid-to-late 2000s, a need to collect, query and monetize a large amount of company data began to emerge. This new data was structured, semi-structured and unstructured and came from different data sources at blinding speeds. 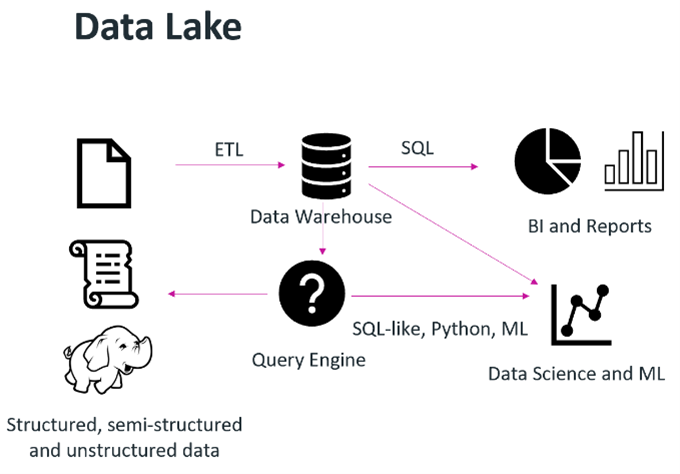 Organizations wanted to leverage data science or machine learning techniques to provide some desired output or piece of monetizable information, such as a formula that would predict the failure rate of a widget based on millions of data points. The term “data lake” was coined, and a data lake’s purpose was to store data in raw formats. The challenge here was that data lakes are good for storing data, not enforcing data quality or running transactions on top of them.
Organizations wanted to leverage data science or machine learning techniques to provide some desired output or piece of monetizable information, such as a formula that would predict the failure rate of a widget based on millions of data points. The term “data lake” was coined, and a data lake’s purpose was to store data in raw formats. The challenge here was that data lakes are good for storing data, not enforcing data quality or running transactions on top of them.
Coming back to the present, object storage and the standardization of the S3 API for communication have changed the game. From a storage perspective, object stores can store a variety of data sets, everything from structured to unstructured data. From an analytics platform/BI tool perspective, it is now possible to tap into the entire data set via the S3 API.
HOW does this all come together?
 S3-based object storage enables the creation of a modern data lakehouse, where storage can be decoupled from compute, diverse analytic workloads can be supported and tools/platforms are able to access data directly with standard S3 API calls.
S3-based object storage enables the creation of a modern data lakehouse, where storage can be decoupled from compute, diverse analytic workloads can be supported and tools/platforms are able to access data directly with standard S3 API calls.
WHERE does this all happen?
This all happens on premises, where Cloudian underpins a data lakehouse by providing scalable, cost-effective storage which is accessible by the S3 API.
Use Cases
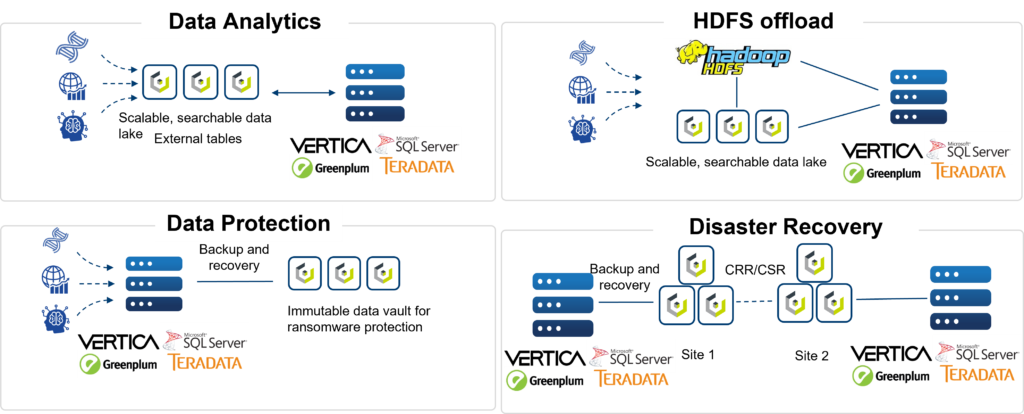
Check out Cloudian’s data lakehouse/data analytics-focused solution briefs at: Hybrid Cloud Storage for Data Analytics