

Gary Ogasawara
CTO, Cloudian
Never before have sensors and apps been able to generate new data as prolifically as now. Looking around my home office now, there is a Macbook running 3 programs writing logs and processing requests and responses, a desktop computer running a web browser with 8 tabs of separate processes, an Amazon Echo listening for voice commands, an Apple iPhone with its own voice recognition assistant and other apps running, an Apple Watch recording my motion and heart rate, a switch with a light sensor, a networked smoke alarm, and a networked air temperature sensor. All of these devices and apps are reading in input data and writing out new data. The same ubiquity of data-generating sensors and apps is happening elsewhere, such as autonomous cars where a single car’s LIDAR sensors alone can create over 10 TB/day or the average factory where 1 TB/day is generated.
Despite this proliferation of data, only a small fraction is being used for decision making because the data cannot be stored or transmitted efficiently. As a result, the full value of analyzing the data for timely decision making has not been realized. Some examples:
- “99 percent of data collected from 30,000 sensors on an oil rig was lost before reaching operational decision-makers.” — McKinsey Global Institute Report
- “The average factory generates 1 TB of production daily, but only 1% is analyzed and acted upon in real-time.” — IBM
The problem is that the legacy model of moving data to a central hub to be worked on by compute processes (i.e., moving data to compute) is broken. This centralized, sequential processing model worked in the past because processing required large, physical resources and the volume of data was limited. In addition, the code was not portable — it could only be run on the hardware platform for which it was designed.
With portable microservices, virtual environments, and distributed computing platforms like Spark, there’s a new model that flips the legacy model by moving compute to data, recognizing the reality of data gravity. Code is portable, most prominently as Kubernetes-managed containers, and able to run on multiple environments, including public clouds, private data centers, and small processors. With distributed computing platforms, compute tasks can be divided and distributed across different compute resources. Finally, the new model enables data to be processed at the edge where it is being generated and decisions to be made at edge processors. This is particularly important because the volume of data is large and continuous, and there isn’t a network vast enough, now or in the foreseeable future, to transmit all the data to a central hub or cloud. In short, the new model affirms the reality of data gravity, in which compute is pulled to the data.
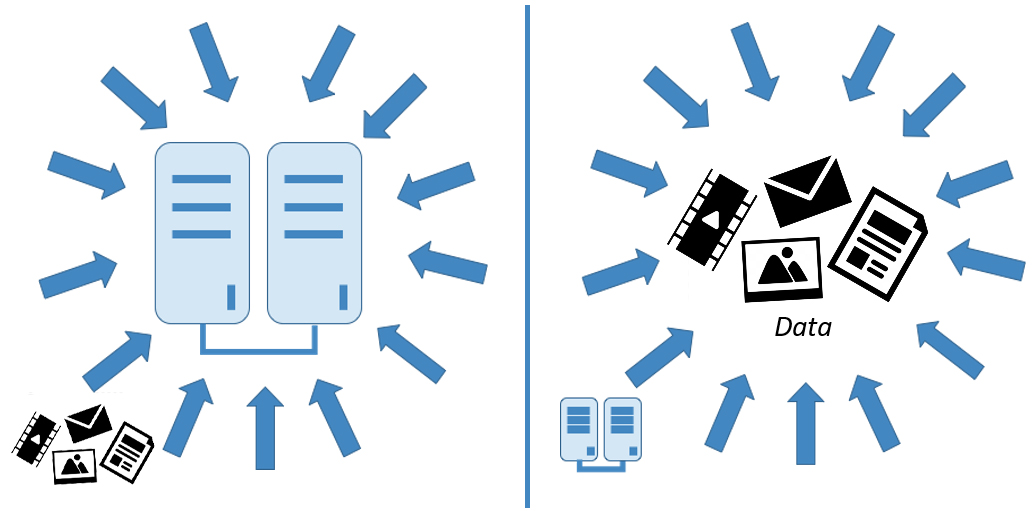
| Legacy Model: Move data to compute | New Model: Move compute to data |
|---|---|
|
|
Compared to the legacy model where data is transferred to a hub and then processed, edge processing is faster, cheaper, and more secure.
- Faster: Real-time decision making in applications like manufacturing or autonomous driving cannot afford the delay of transmitting data back and forth to another location.
- Cheaper: Moving data is expensive, incurring network charges. Also, data storage is not a static one-time cost, but rather measured by volume and time (e.g., GB-days).
- More secure: When data is moved or replicated, it’s inherently less secure than keeping the data in place. In addition, if data needs to be stored in a hub that is shared with other users, there is more risk, especially in controlling access.
Edge processors should be used as additive and complementary to a networked central hub. It’s not all edge or all hub. Edge processing is best for isolated, local decision-making like filtering data (e.g., discarding some normal sensor readings) and applying efficiently executable decision models (e.g., using a trained ML model to detect anomalies). Hub processing is best for large-scale, centralized analysis (e.g., training an ML model from diverse data sources) and long-term, archival storage (e.g., data that must be kept for compliance purposes).
The below diagram shows an example of a hybrid edge and hub model. An inner loop of edge processors and sensors provides real-time decision making by applying a pre-trained ML model that filters and summarizes input data before sending it to the hub. An outer loop of the hub and the edge processors trains the ML models and long-term data storage. On schedule or on-demand, the updated ML models are pushed to the edge processors.
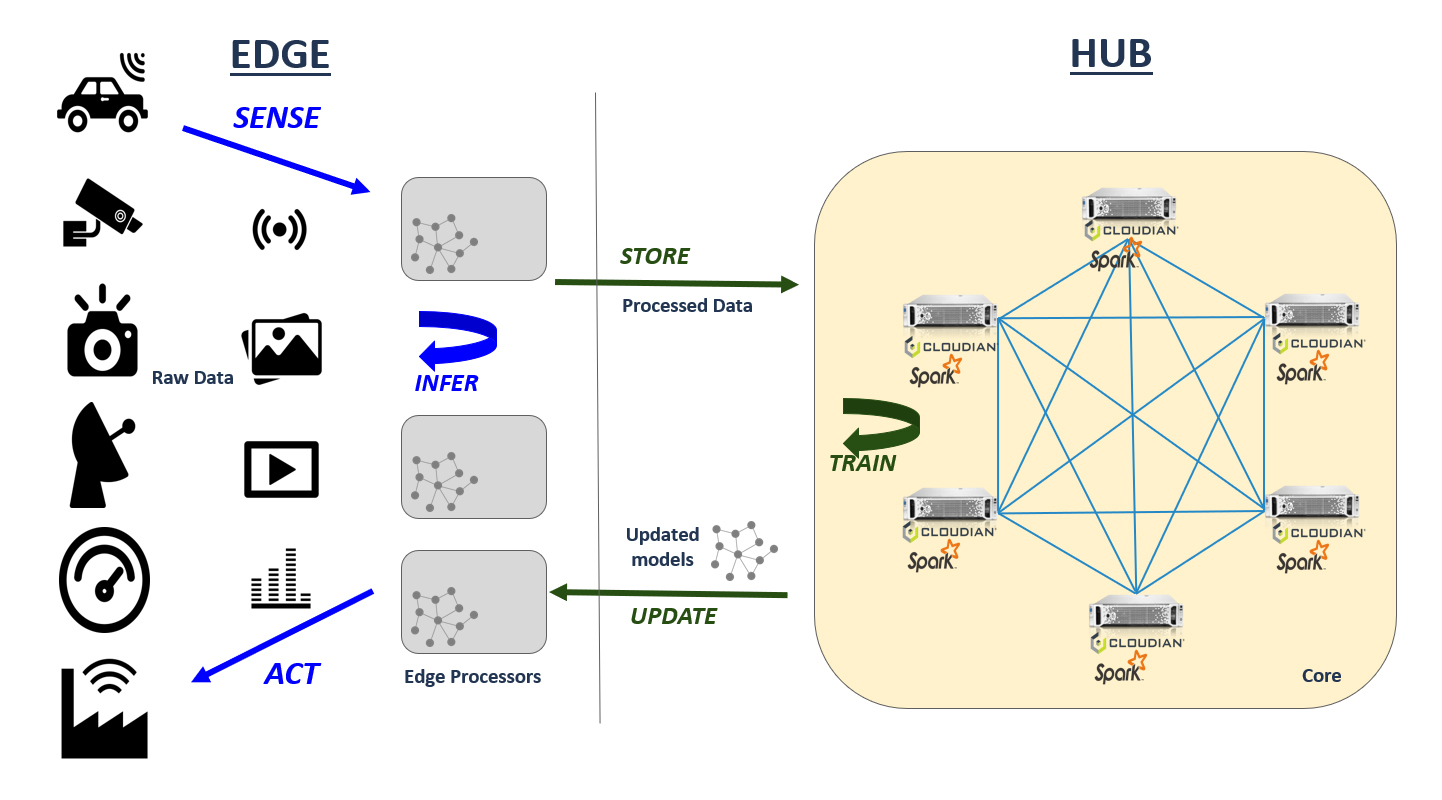 Many analytics tasks are best implemented as a hybrid edge and hub model. One pattern is using streaming data for ML where the input is a continuous stream of transaction log data from multiple sources — e.g., analyzing views and clicks on a web page to determine the best performing UI elements. The data needs to be aggregated at the hub to gather a variety of sources, and edge processors can summarize and filter data transferred to the hub. Another example is video surveillance where multiple cameras capture live video. Edge processors can apply trained ML models for event detection and real-time alerts, and the hub trains updated ML models and handles archival storage of video data.
Many analytics tasks are best implemented as a hybrid edge and hub model. One pattern is using streaming data for ML where the input is a continuous stream of transaction log data from multiple sources — e.g., analyzing views and clicks on a web page to determine the best performing UI elements. The data needs to be aggregated at the hub to gather a variety of sources, and edge processors can summarize and filter data transferred to the hub. Another example is video surveillance where multiple cameras capture live video. Edge processors can apply trained ML models for event detection and real-time alerts, and the hub trains updated ML models and handles archival storage of video data.
To summarize, rather than a move to the cloud, real-time analytics demand a move to the edge, pulling compute to the data. With the proliferation of data sources at the edge generating continuous, high volume data, edge processors need to be integrated with hubs/clouds to form a hybrid architecture.
At Cloudian, we’re working to extend our expertise in geo-distributed storage for on-premises and hybrid cloud environments to support edge processing in a hybrid edge and hub model.
To see how Cloudian can help you manage, protect and leverage your growing data volumes, go here to register for a free trial