
What Is the Shared Nothing Architecture?
The concept of shared nothing architecture isn’t new. It’s been around since the 1980s, when it was first coined by Michael Stonebraker, a computer scientist at the University of California, Berkeley. However, with the advent of big data and the demands for more efficient data processing, this architecture has gained renewed attention.
The shared nothing architecture is all about independence and autonomy. Each node, whether it’s a computer, a server, or a database, has its own dedicated resources. These resources, such as memory, storage, and processing power, are not shared with other nodes. As a result, there are fewer bottlenecks and less contention between nodes, leading to improved performance and scalability.
This is part of a series ot articles about data backup
In this article:
- Shared Nothing Architecture vs. Other Computing Architectures
- Advantages of a Shared Nothing Architecture
- Challenges of a Shared Nothing Architecture
- Best Practices in Implementing a Shared Nothing Architecture
Shared Nothing Architecture vs. Other Computing Architectures
The following diagram shows a schematic representation of the shared nothing architecture vs. other common architectures. Below we explain the differences in more detail.
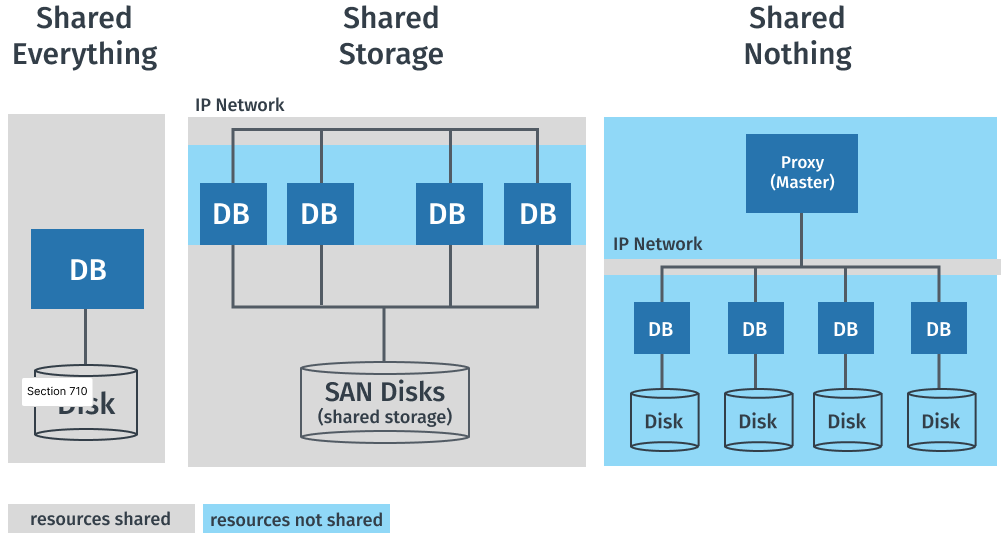

Shared Nothing Architecture vs. Shared-Everything Architecture
In a shared everything architecture, all nodes have access to a common pool of resources, which includes memory and storage. This can lead to contention and bottlenecks, as nodes compete for access to shared resources.
In contrast, in shared nothing architecture, each node has its own dedicated resources, eliminating the potential for contention. This results in better performance, scalability, and fault tolerance. However, this architecture requires careful data partitioning and management to ensure balanced load across nodes.
Shared Nothing Architecture vs. Shared-Storage Architecture
Shared-storage architecture is another distributed computing model where all nodes access shared disks for data storage. This leads to a single point of contention, the disk, which can be a bottleneck in terms of performance and scalability.
On the other hand, shared nothing architecture eliminates this bottleneck by allocating dedicated storage to each node. This not only improves performance but also enhances fault tolerance, as a failure in one node doesn’t affect the others.
Shared Nothing Architecture vs. Shared-Memory Architecture
Another variation on the shared storage architecture is the shared memory architecture, a model in which all nodes share a common memory pool. Because memory has much lower latency than disk, this architecture can provide better performance than a shared storage architecture. However, this architecture can still lead to contention as nodes compete for memory access.
The shared nothing architecture addresses this issue by assigning dedicated memory to each node. This autonomy reduces contention and improves performance, while also enhancing fault tolerance and reliability.
Related content: Read our guide to backup storage
Advantages of a Shared Nothing Architecture
Scalability and Performance Efficiency
One of the main advantages of shared nothing architecture is its scalability. As each node operates independently with its own resources, you can easily add more nodes to the system to handle increased load. This makes shared nothing architecture an ideal choice for systems that need to scale out to accommodate growth.
In terms of performance efficiency, shared nothing architecture excels due to the absence of contention for shared resources. Each node can process its own data without interference from other nodes, leading to faster processing times and improved overall performance.
Fault Tolerance and Reliability
A shared nothing architecture also offers robust fault tolerance. Since each node operates independently, the failure of one node doesn’t affect the rest of the system. This means that even if one node goes down, the system can continue to function, providing a high level of reliability.
Moreover, as each node has its own copy of the data, it can continue to operate even in the event of a network failure. This redundancy further enhances the reliability of shared nothing architecture, ensuring that your system remains up and running, even in the face of adversity.
Cost-Effectiveness and Resource Optimization
In a shared nothing architecture, each node has its own dedicated resources, so there’s no need for expensive shared infrastructure. This reduces the total cost of ownership, making shared nothing architecture an economical choice for distributed computing.
Furthermore, shared nothing architecture optimizes resource utilization. As each node is responsible for its own processing, resources are used efficiently, with no wastage. This makes shared nothing architecture a resource-efficient choice, ensuring that you get the most out of your computing resources.
Challenges of a Shared Nothing Architecture
Complexity in Implementation and Maintenance
One of the primary hurdles in the adoption of shared nothing architecture is its inherent complexity. The setup of each node with its data and resources require meticulous planning and execution. The individual nodes, while functioning independently, need to work coherently to ensure the overall system’s smooth operation.
In addition, each node, with its unique set of data and resources, needs to be maintained independently. The need for individual care increases the maintenance cost, both in terms of time and resources. Additionally, any alterations or enhancements in the system architecture require changes to be made in each node, adding to the complexity.
Data Consistency and Synchronization Issues
Data consistency is another significant challenge in shared nothing architecture. Since each node manages its data, maintaining synchronization across all nodes can be a complex task. If updates are made to the data in one node, they need to be replicated across all other nodes to maintain consistency. This can be time-consuming and, in some cases, may lead to data inconsistencies if not managed properly.
Moreover, the issue of data partitioning arises. A single piece of data might be divided among multiple nodes. Consequently, retrieving or updating that data becomes a complex task as it involves multiple nodes. If not handled correctly, this can lead to data inconsistency and loss of data integrity.
Network Dependency and Bottlenecks
A shared nothing architecture relies heavily on network communication. Each node communicates with others through the network to accomplish tasks, share status, and maintain consistency. Therefore, a robust and reliable network is critical for the successful operation of such a system.
However, network dependency can lead to bottlenecks, especially when large volumes of data are being transferred between nodes. This can hinder system performance and slow down processes. Moreover, if the network becomes unavailable or experiences issues, it can cause the entire system to fail or degrade in performance.
Best Practices in Implementing a Shared Nothing Architecture
Effective Data Partitioning
Effective data partitioning involves dividing the data into manageable and logical segments that can be distributed among the nodes. This allows for efficient data management and minimizes the risk of data inconsistency.
To implement effective data partitioning, you need to understand your data thoroughly. Analyzing the data usage patterns and access frequency can provide insights into how the data should be partitioned. The goal is to minimize data movement across nodes and ensure that the most frequently accessed data is readily available.
Optimizing Network Communication
Given the critical role of network communication in shared nothing architecture, it’s imperative to optimize it to ensure smooth operation. This involves efficient data transfer techniques, robust network infrastructure, and effective error handling mechanisms.
By reducing the amount of data transferred between nodes, you can minimize network traffic and avoid bottlenecks. This can be achieved through efficient data partitioning and local processing of data. Furthermore, investing in a robust network infrastructure that can handle high volumes of data can significantly improve system performance.
Node Autonomy and Independence
Node autonomy is a fundamental principle of shared nothing architecture. Each node should be capable of operating independently, managing its resources, and making decisions without relying on other nodes. This enhances system reliability and scalability.
To ensure node autonomy, you need to equip each node with the necessary resources and capabilities. This includes sufficient storage and processing power, as well as the right software tools. Moreover, you need to implement effective error handling mechanisms that allow nodes to handle failures independently.
Balancing Load and Managing Resources
In shared nothing architecture, balancing load and managing resources effectively is crucial to ensure optimal system performance. This involves distributing the workload evenly among the nodes and ensuring that each node has the necessary resources to handle its tasks.
Load balancing can be achieved through effective data partitioning and task scheduling. By distributing data and tasks evenly, you can avoid overloading certain nodes and ensure a smooth operation. Furthermore, regular monitoring and management of resources can help detect and address any resource shortages or inefficiencies.
Shared Nothing Data Protection with Cloudian HyperStore
Data protection requires powerful storage technology. Cloudian’s storage appliances, based on a shared nothing architecture, are easy to deploy and use, let you store Petabyte-scale data and access it instantly. Cloudian supports high-speed backup and restore with parallel data transfer (18TB per hour writes with 16 nodes).
Cloudian provides durability and availability for your data. HyperStore can backup and archive your data, providing you with highly available versions to restore in times of need.
In HyperStore, storage occurs behind the firewall, you can configure geo boundaries for data access, and define policies for data sync between user devices. HyperStore gives you the power of cloud-based file sharing in an on-premise device, and the control to protect your data in any cloud environment.
Learn more about data protection with Cloudian.