Henry Chu, Director of Solution Management, Cloudian

How to Get Full GitHub Benefits On-Premises
GitHub has traditionally been known as a commonly used cloud service to store, manage and share code using tools like Git. It is this service that’s most familiar to many developers. However, GitHub also has an offering that provides the ability to use GitHub on-premises with GitHub Enterprise Server (GHES) for enterprises that require a solution behind their firewall due to network restrictions or generally want tighter control over their data and access to it. GHES includes GitHub Actions and GitHub Packages, both of which can use not only public cloud storage but also on-prem S3-compatible object storage, which is what’s needed for a complete on-prem deployment of GHES. Cloudian HyperStore provides a validated on-prem object storage for GHES with the highest levels of S3 compatibility. In addition, HyperStore can also be deployed across multiple public clouds, providing a distributed S3 service for GHES with a single namespace across multi-cloud infrastructure.
This blog focuses on how to deploy HyperStore with GitHub Actions and GitHub Packages on-prem.

GitHub Actions
GitHub Actions automates CI/CD workflows and are created from building, testing, pull, and deploying requests. Cloudian HyperStore provides the on-prem S3-compataible object storage for GitHub Actions to store data such as artifacts and logs.
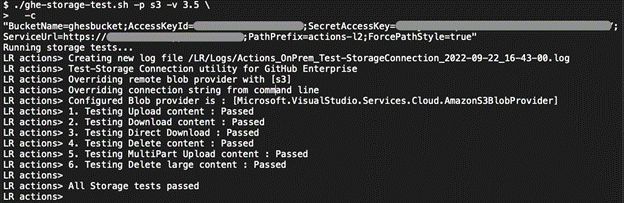
Cloudian has validated the necessary S3 operations used by GitHub Actions with HyperStore (see Cloudian’s validation at GHES Storage Partners). Using GitHub’s ghe-storage-test.sh, all storage operations have passed.
To configure GitHub Actions with Cloudian HyperStore, go to GHES Site admin interface.

On Site admin, go to Management console.
At the Management console, go to Applications and Enable GitHub Actions. Under Artifact & Log Storage, choose Amazon S3.
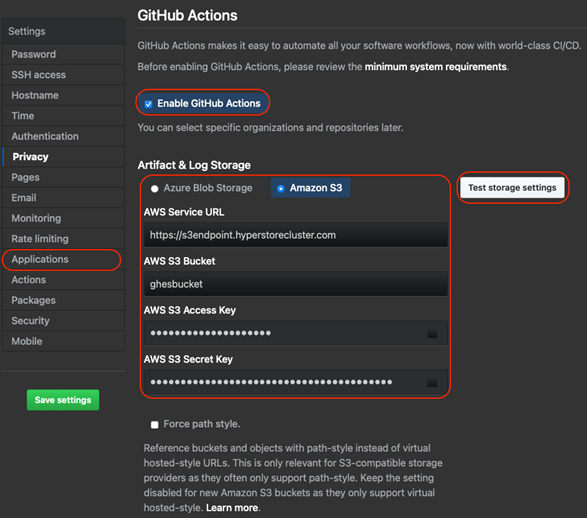
Enter the following fields:
- AWS Service URL: Enter the S3 endpoint configured for your HyperStore Cluster.
- AWS S3 Bucket: Enter the name of the bucket to be used for GitHub Actions
- AWS S3 Access Key: Enter the access key for the HyperStore user for the given bucket
- AWS S3 Secret Key: Enter the secret key for the HyperStore user for the given bucket
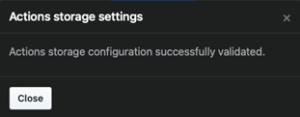
Click on Test storage settings to validate the configuration. Then save the settings.
GitHub Packages
GitHub Packages gives you a safe way to publish and share application packages within your organization. With Cloudian HyperStore, you can achieve a complete on-prem deployment.
To configure GitHub Packages with HyperStore, go to Management console and then to Packages. Enable GitHub Packages.
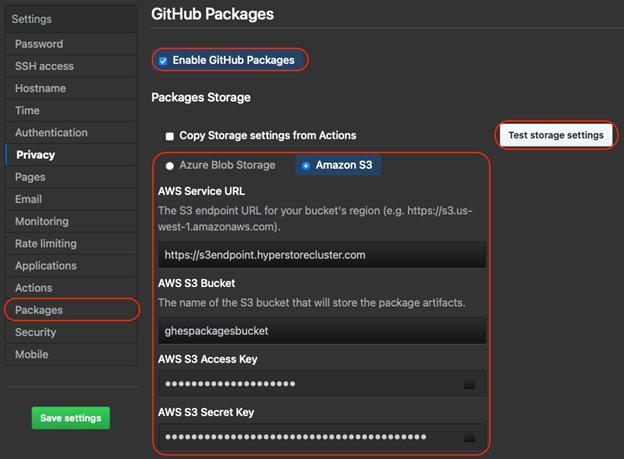
Choose Amazon S3 for your storage. Enter the following fields:
- AWS Service URL: Enter the S3 endpoint configured for your HyperStore Cluster.
- AWS S3 Bucket: Enter the name of the bucket to be used for GitHub Packages.
- AWS S3 Access Key: Enter the access key for the HyperStore user for the given bucket
- AWS S3 Secret Key: Enter the secret key for the HyperStore user for the given bucket
Click on Test storage settings to validate the configuration and then save the settings.
Summary
With GitHub Enterprise Server and Cloudian HyperStore, enterprises now have a solution to store, manage, and share code with full control behind the security of their firewall. HyperStore provides the S3-compatible object storage on-prem (or distributed over multi-cloud) for GitHub Actions, a solution for CI/CD workflows. Similarly, HyperStore can also be used as a storage target for GitHub Packages, a repository for application packages.
To learn more about HyperStore’s features and benefits, go to Scalable Enterprise Object Storage | Cloudian HyperStore.

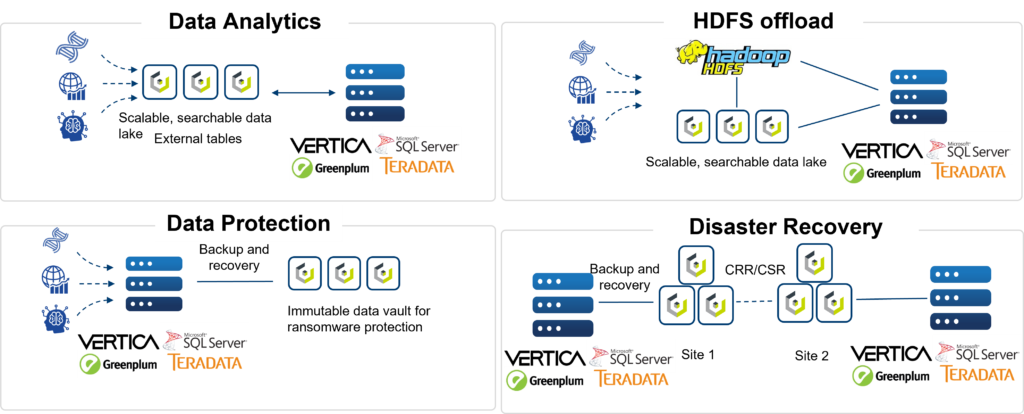
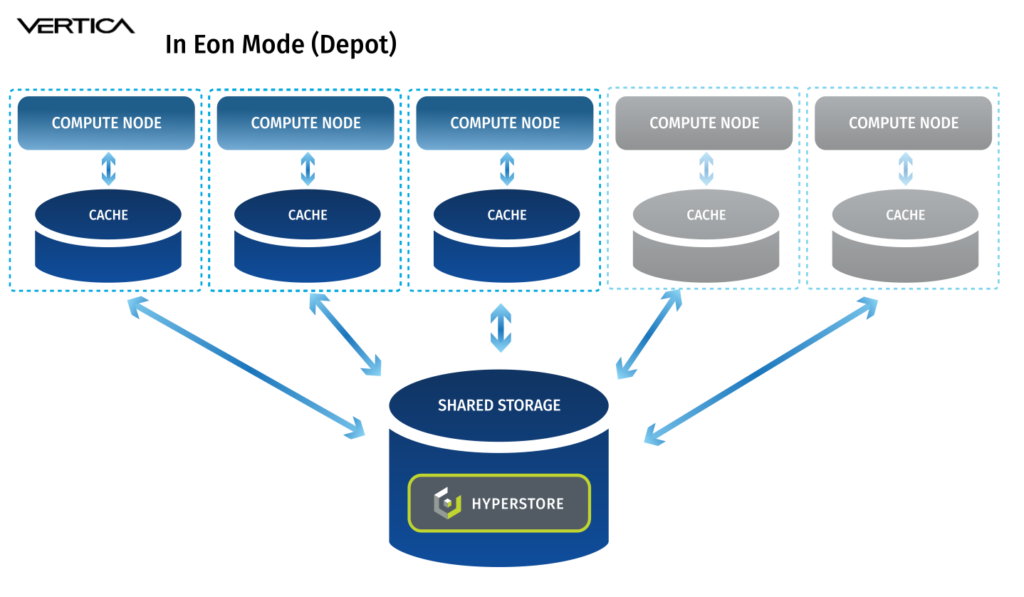 In the data analytics space, Vertica is known for performance, whether it is run in “Enterprise Mode” or “Eon Mode.” In Enterprise Mode each database node stores a portion of the dataset and performs a portion of the computation. In Eon Mode, Vertica brings its cloud architecture to on-premises deployments and decouples compute and storage. In Eon Mode, each Vertica node can access a shared communal storage space via S3 API. The advantages are: a) compute can be scaled as required without having to scale storage, meaning no more server sprawl and b) storage can be consolidated into a single platform and accessed by various data tools:
In the data analytics space, Vertica is known for performance, whether it is run in “Enterprise Mode” or “Eon Mode.” In Enterprise Mode each database node stores a portion of the dataset and performs a portion of the computation. In Eon Mode, Vertica brings its cloud architecture to on-premises deployments and decouples compute and storage. In Eon Mode, each Vertica node can access a shared communal storage space via S3 API. The advantages are: a) compute can be scaled as required without having to scale storage, meaning no more server sprawl and b) storage can be consolidated into a single platform and accessed by various data tools:
 Let’s consider the following scenario… we have an ORC dataset, which was generated by an Apache Hive instance, stored on Cloudian, and we need to connect to it with Vertica. To analyze this dataset in-place, use the following Vertica syntax to connect to the ORC dataset:
Let’s consider the following scenario… we have an ORC dataset, which was generated by an Apache Hive instance, stored on Cloudian, and we need to connect to it with Vertica. To analyze this dataset in-place, use the following Vertica syntax to connect to the ORC dataset:

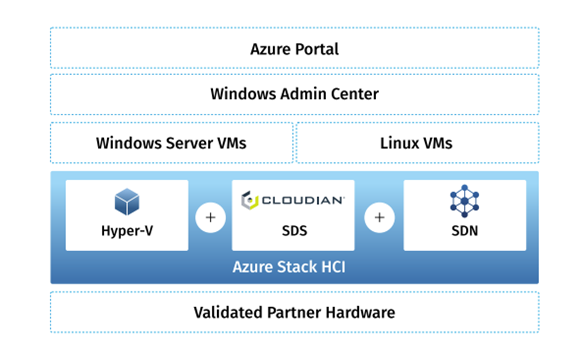 HyperStore employs policy-based tools to replicate or tier data to Azure for offsite disaster recovery, capacity expansion or data analysis in the cloud. HyperStore offers limitless scalability, multi-tenancy and military-grade security. This includes the ability to isolate storage pools using local and remote authentication methods such as Password, AD, LDAP, IAM and certificate-based authentication.
HyperStore employs policy-based tools to replicate or tier data to Azure for offsite disaster recovery, capacity expansion or data analysis in the cloud. HyperStore offers limitless scalability, multi-tenancy and military-grade security. This includes the ability to isolate storage pools using local and remote authentication methods such as Password, AD, LDAP, IAM and certificate-based authentication.

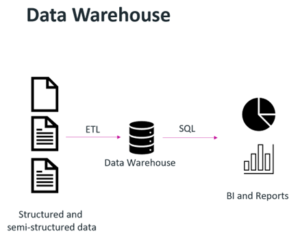
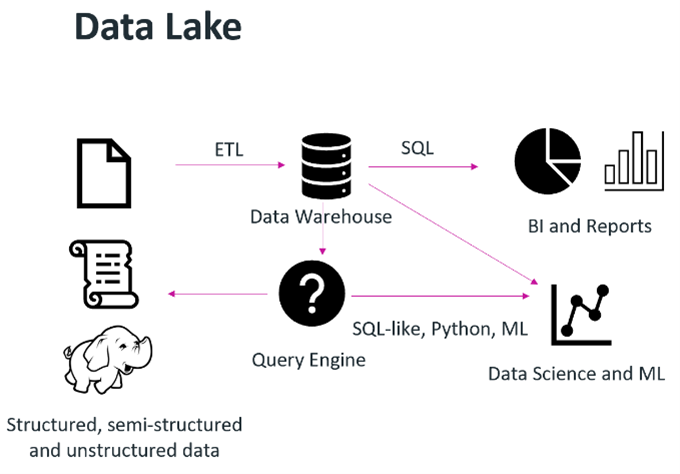 Organizations wanted to leverage data science or machine learning techniques to provide some desired output or piece of monetizable information, such as a formula that would predict the failure rate of a widget based on millions of data points. The term “data lake” was coined, and a data lake’s purpose was to store data in raw formats. The challenge here was that data lakes are good for storing data, not enforcing data quality or running transactions on top of them.
Organizations wanted to leverage data science or machine learning techniques to provide some desired output or piece of monetizable information, such as a formula that would predict the failure rate of a widget based on millions of data points. The term “data lake” was coined, and a data lake’s purpose was to store data in raw formats. The challenge here was that data lakes are good for storing data, not enforcing data quality or running transactions on top of them. S3-based object storage enables the creation of a modern data lakehouse, where storage can be decoupled from compute, diverse analytic workloads can be supported and tools/platforms are able to access data directly with standard S3 API calls.
S3-based object storage enables the creation of a modern data lakehouse, where storage can be decoupled from compute, diverse analytic workloads can be supported and tools/platforms are able to access data directly with standard S3 API calls.