On-prem S3 Data Lakehouse for Modern Analytics and More

Data Lakehouse Origin
The modernization of the data analytics architecture started in the cloud. This was driven by the limits of traditional data warehouses with a conventional appliance-based approach, which could not provide the needed scalability, was cumbersome to work with and expensive, and could only serve one use case. In response, companies such as Snowflake and Databricks took the traditional OLAP operations and showed the benefits of combining the flexibility, cost-efficiency, and scale of a data lake built on cloud storage (based on the S3 API) with the data management and ACID transactions of a data warehouse, thereby giving us the modern data lakehouse.
However, not everyone is able to or willing to move their data to the cloud, for data gravity, security, and/or compliance reasons. Customers – especially enterprise customers – have started replicating the same architecture that Snowflake pioneered within their own data centers and/or in hybrid cloud configurations. Specifically, by using S3-compatible object storage platforms like Cloudian HyperStore, customers can now implement an S3 data lakehouse and get the same efficiencies with greater control.
The Many Benefits of a Data Lakehouse Architecture
An on-prem data lakehouse solution offers the same cloudification of the data analytics environment, but behind the security of users’ firewalls. This gives organizations full control to implement the right security protocols, compliance measures, and audit-logging for their needs.
In addition to providing public cloud-like scalability, the data lakehouse architecture also gives customers the ability to scale the data lake (storage) independent of the compute, a big difference from the shared-everything architectures that bogged down the big data world a few years ago.
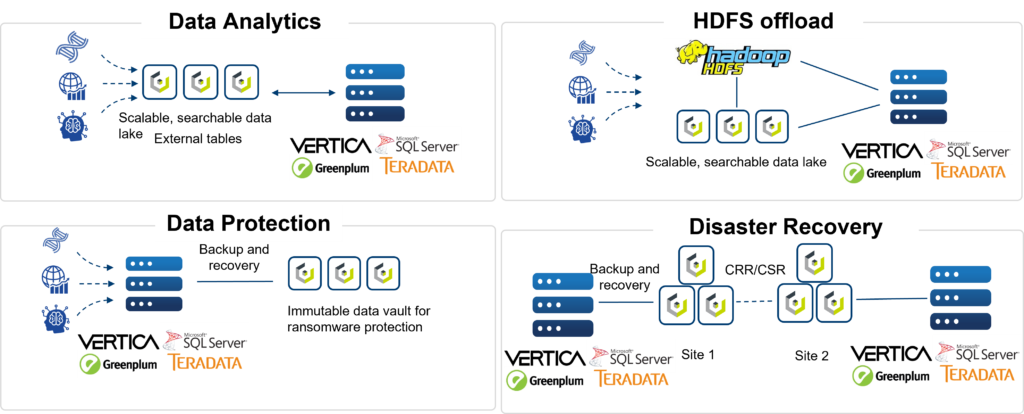
Standardization on the S3 API — the de facto storage standard of the cloud — enables enterprises to continue to build and reuse applications already built for the cloud with their on-prem data lakehouse. Standardization also allows for use cases beyond analytics, such as a repository for Splunk data and immutable backup storage for ransomware protection — generally a repository for all unstructured data (media, images, videos, etc.) — and all supported in the same S3 data lakehouse.
These are just a few reasons for considering S3-compatible storage such as Cloudian for your data lakehouse solution. You can read about others at 7 Reasons to Run Data Analytics on a Cloudian S3 Data Lakehouse. In addition, to learn more about data lakehouses and how Cloudian can help you meet your data analytics needs, please visit https://www-cloudian-com-staging.go-vip.net/solutions/data-lakehouse/.

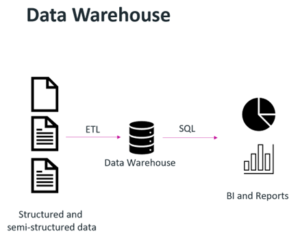
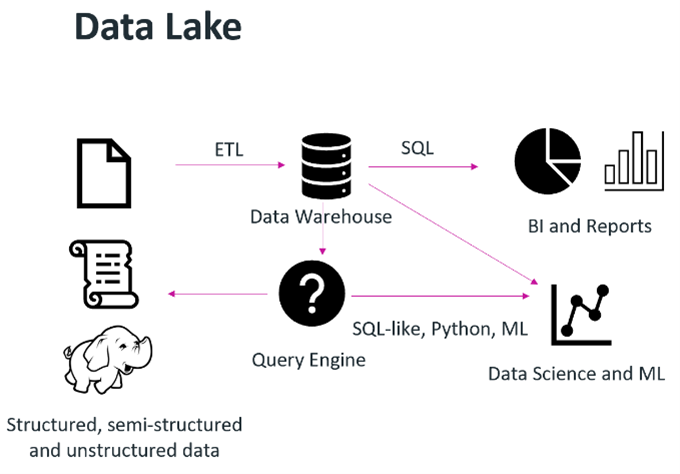 Organizations wanted to leverage data science or machine learning techniques to provide some desired output or piece of monetizable information, such as a formula that would predict the failure rate of a widget based on millions of data points. The term “data lake” was coined, and a data lake’s purpose was to store data in raw formats. The challenge here was that data lakes are good for storing data, not enforcing data quality or running transactions on top of them.
Organizations wanted to leverage data science or machine learning techniques to provide some desired output or piece of monetizable information, such as a formula that would predict the failure rate of a widget based on millions of data points. The term “data lake” was coined, and a data lake’s purpose was to store data in raw formats. The challenge here was that data lakes are good for storing data, not enforcing data quality or running transactions on top of them. S3-based object storage enables the creation of a modern data lakehouse, where storage can be decoupled from compute, diverse analytic workloads can be supported and tools/platforms are able to access data directly with standard S3 API calls.
S3-based object storage enables the creation of a modern data lakehouse, where storage can be decoupled from compute, diverse analytic workloads can be supported and tools/platforms are able to access data directly with standard S3 API calls.