This is a guest post by Tim Wessels, the Principal Consultant at MonadCloud LLC.
Private cloud storage can scale-out to meet the demands for additional storage capacity, but can it scale-down to meet the needs of small and medium-sized organizations who don’t have petabytes of data?
The answer is, yes it can, and you should put cloud storage vendor claims to the test before making your decision to build a private storage cloud.

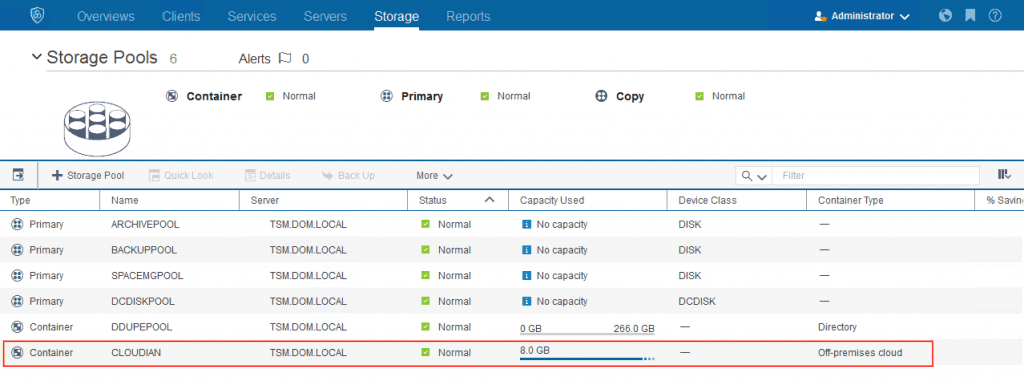
A private storage cloud that can cost-efficiently store and manage data on a smaller scale is important if you don’t need petabyte-capacity to get started. A petabyte is a lot of data. It is equivalent to 1000 terabytes. If you have 10 or 100 terabytes of data to manage and protect, a scale-down private storage cloud is what you need to do that. And in the future, when you need additional storage capacity, you must be able to add it without having to rip-and-replace the storage you started with.
The characteristics of scale-down, private cloud storage make it attractive for organizations with sub-petabyte data storage requirements.

You can start with a few storage servers and grow your storage capacity using a mix of storage servers and storage capacities from different manufacturers. A private storage cloud is storage server hardware agnostic so you can buy what you need when you need it.
Scale-down, private cloud storage should employ a “peer-to-peer” architecture, which means the same software elements are running on each storage server.
A “peer-to-peer” storage architecture doesn’t use complex configurations that require specialized and/or redundant servers to protect against a single point of failure. Complexity is not a good thing in data storage. After all, why would you choose a private cloud storage solution that is too complex for your needs?
Scale-down, private cloud storage should also be easy-to-use and easy-to-manage.
Easy-to-use means simple procedures to add, remove or replace storage servers. It also means using storage software with built-in intelligence that can protect your data and keep it accessible without a lot of fine tuning or tinkering to do it.
Easy-to-manage means you don’t need a dedicated storage administrator to keep your private cloud storage cluster running. An in-house computer systems administrator can do it or you can hire out administration to a managed services provider who can do it remotely.
So just how small is small when it comes to building your own private cloud storage? Small is a relative term, but a practical minimum from a hardware perspective would be about 10 terabytes of usable storage. There is nothing hard and fast about starting with 10 terabytes of usable storage, but once you start moving data into your private storage cloud, you should have an amount of usable storage that is appropriate for the uses you have in mind.
If you have never built your own private cloud storage, you will need to determine which private storage cloud vendor has a simple, easy-to-use and easy-to-manage, private cloud storage solution that will work for you.
The best way to help you make your decision is to conduct a Proof-of-Concept (POC) to determine which vendor will best meet your requirements for private cloud storage. Every vendor will tell you how easily their cloud storage scales out, but they may not mention if it can easily scale-down to meet the needs of organizations with sub-petabyte data storage requirements.
A Proof-of-Concept is not a whiteboard exercise or a slide presentation. A POC is done by having vendors showing you how their storage software running on their storage hardware or your storage hardware works. A vendor who cannot commit to a small-scale POC may not be a good fit for your requirements.
The applications you plan to use with your private storage cloud should also be included in your POC. If you are not writing your own applications, then it is important to consider the size of the application “ecosystem” supported by the storage vendors participating in your POC.
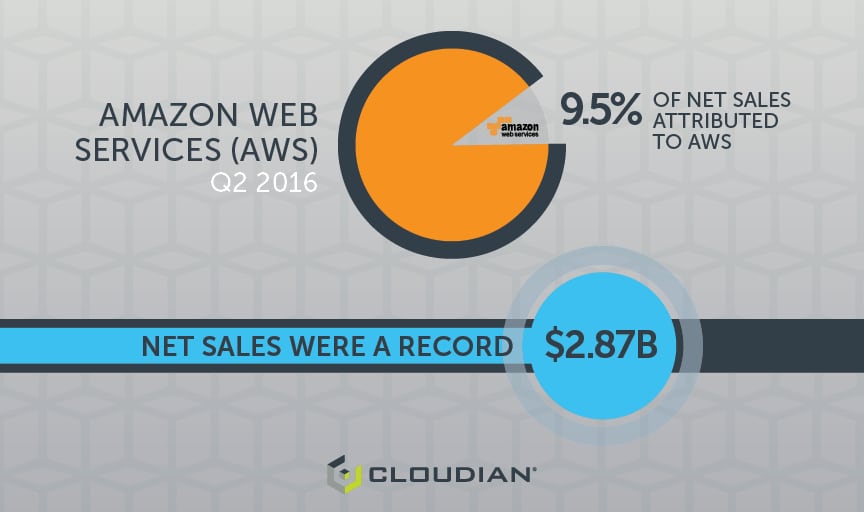
After ten years in the public cloud storage business, Amazon Web Services (AWS) has the largest “ecosystem” of third-party applications written to use their Simple Storage Service (S3). The AWS S3 Application Programming Interface (API) constitutes a de facto standard that every private storage cloud vendor supports to a greater or lesser degree, but only Cloudian guarantees that applications that work with AWS S3 will work with Cloudian HyperStore. The degree of AWS S3 API compliance among storage vendors is something you can test during your POC.
Running a POC will cost you some time and money, but it is a worthwhile exercise because storage system acquisitions have meaningful implications for your data. It is worth spending a small percentage of the acquisition cost on a POC in order to make a good decision.
The future of all data storage is being defined by software. Storage software running on off-the-shelf storage server hardware defines how a private storage cloud works. A software-defined private storage cloud gives you the features and benefits of large public cloud storage providers, but does it on your premises, under your control, and on a scale that meets your requirements. Scale-down private cloud storage is useful because it is where many small and medium-sized organizations need to start.
Tim Wessels is the Principal Consultant at MonadCloud LLC, which designs and builds private cloud storage for customers using Cloudian HyperStore. Tim is a Cloudian Certified Engineer and MonadCloud is a Preferred Cloudian Reseller Partner. You can call Tim at 978.413.0201, email twessels@monadcloud.net, tweet @monadcloudguy, or visit http://www.monadcloud.com
YOU MAY ALSO BE INTERESTED IN:
Object Storage vs File Storage: What’s the Difference?


 Grant Jacobson, Director of Technology Alliances and Partner Marketing, Cloudian
Grant Jacobson, Director of Technology Alliances and Partner Marketing, Cloudian Amit Rawlani, Director of Solutions & Technology Alliances, Cloudian
Amit Rawlani, Director of Solutions & Technology Alliances, Cloudian
 Jon Toor, CMO, Cloudian
Jon Toor, CMO, Cloudian