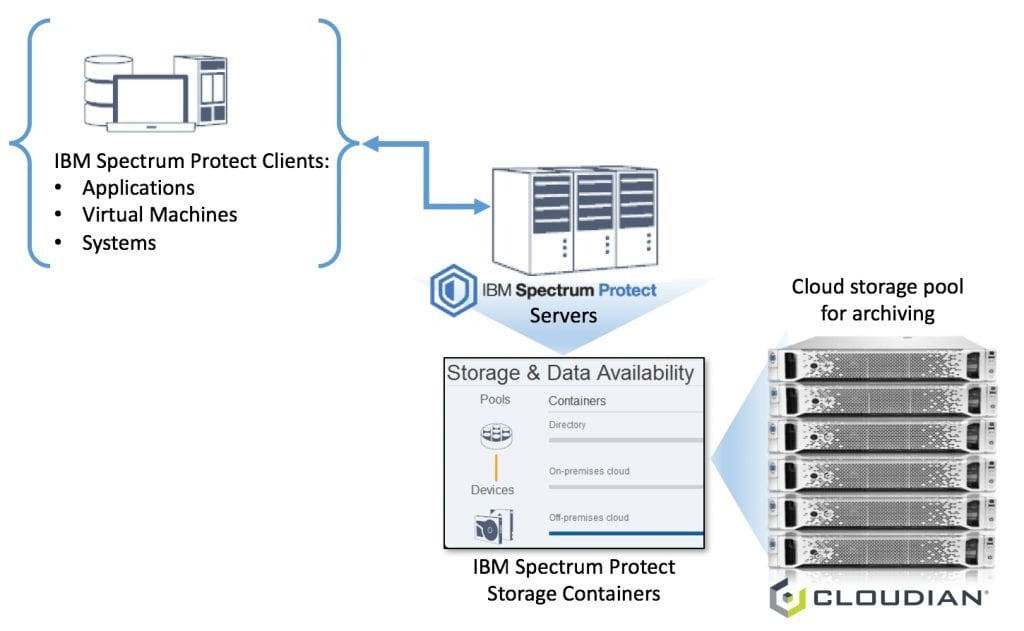
There’ve been a lot of discussions about Amazon’s Simple Storage Service (S3) and Amazon Web Services (AWS). It seems to me that everyone is saying that they are Amazon S3-compatible or that they work with S3 storage. That makes me wonder, what is the best way to validate a solution or test it out to see if the storage solution will meet my object storage needs? Well, why not just use Amazon’s own S3APIs and AWS Command Line Interface (CLI)?
AWS CLI is a unified tool developed to help manage AWS services. I believe this is the best way to test out any solution that says they are an S3 compatible storage such as Cloudian HyperStore. So let’s hop on to it and get started. The following shows the steps on how to install and use AWS CLI with Cloudian HyperStore on your Linux server.
Prerequisite:
You will need to install PIP to simplify your AWS CLI installation, you can copy the following python script to your Linux server and it will help you install pip and awscli. The script is provided as-is but feel free to copy, modify and improve it to your liking.
import urllib
import os
PIP=’get-pip.py’
urllib.urlretrieve (“https://bootstrap.pypa.io/get-pip.py”, PIP)
os.system(“python get-pip.py”)
os.system(“pwd”)
os.system(“pip install awscli”)
Process:
- Download the following dc_getpip.py to your Linux server. The script has been tested on RHEL and CentOS. The Cloudian S3 region used in this example is s3-region.addomain.local
- Run python dc_getpip.py. This script will download pip and install AWS CLI for you.
- When the AWS CLI is successfully installed, continue with configuring AWS CLI with Cloudian HyperStore.
- Execute aws configure and provide the Cloudian credential along with the Cloudian S3 region information. For example:

- cd ~/./.aws because the config and the credential files for aws is located in your user directory. In this example, this is the root user directory.

- There are 2 files in .aws directory:
- config
- credentials
- Update the config file with the Cloudian region information. Include [cloudian] in your update.

- Update the credentials files with the Cloudian information, include [cloudian] in your update.

- Run the following aws command to validate connectivity to your Cloudian HyperStore cluster. Using s3 ls will list the buckets of the tenant that was configured.
- aws –profile=cloudian –endpoint-url=http://s3-region1.addomain.local s3 ls

- Replace s3-region1.addomain.local with your Cloudian region.
- You can use aws –profile=cloudian –endpoint-url=http://s3-region1.addomain.local s3 cp file s3://bucket to test upload to your s3 bucket.
- aws –profile=cloudian –endpoint-url=http://s3-region1.addomain.local s3 ls
- Your AWS CLI is successfully configured with Cloudian HyperStore S3.
If you are curious to learn more about S3, download Cloudian HyperStore’s community edition and validate the solution for yourself.
Learn more about hybrid cloud management here.