
What is S3 Replication?
S3 Replication is a fully-managed feature available for Amazon Simple Storage Service (S3) customers. It can automatically replicate S3 objects to help you reduce costs, protect your data, and achieve compliance with regulatory requirements.
Here are the two S3 storage replication options:
- Cross-Region Replication (CRR)—copies S3 objects across multiple Amazon Regions (ARs), representing geographically separate Amazon data centers.
- Same-Region Replication (SRR)—copies S3 objects between buckets in different availability zones (AZs), which are separate data centers in the same AR.
AWS also offers a Replication Time Control (RTC) Service Level Agreement (SLA) that guarantees object replication in less than fifteen minutes.
In this article:
- Amazon S3 Cross-Region Replication (CRR) and Same-Region Replication (SRR)
- How to Set Up AWS S3 Replication
- S3 Replication with Cloudian
This is part of an extensive series of articles about S3 Storage.
Amazon S3 Cross-Region Replication (CRR) and Same-Region Replication (SRR)
AWS S3 Cross-Region Replication (CRR)
CRR can help you reduce latency, maintain compliance, enforce security, and implement disaster recovery. The feature lets you replicate objects into other Amazon Regions (ARs), including your object’s metadata and object tags.
How CRR works
You can configure S3 CRR to copy objects into one or more buckets in a different AR, for improved resilience. The feature lets you set up replication between buckets, shared prefixes, and individual objects. You can manage replication for individual objects using object tags.
CRR Use Cases
Here are key use cases for S3 CRR:
- Compliance—the default configuration in S3 is set to store data across multiple geographically-distant Availability Zones (AZs). However, compliance often requires storing data in specific geographical locations—CRR can help achieve this.
- Latency performance—customers and end-users are sometimes located in several geographic locations. CRR can help you improve their user experience by minimizing latency for data access.
Amazon S3 Same-Region Replication (SRR)
Amazon S3 Same-Region Replication (SRR) provides fully automated replication of S3 objects to another AZ, within the same AR. It is available in all AWS commercial regions as well as AWS GovCloud (US).
How SRR works
SRR uses asynchronous replication, meaning that objects are not copied to the other AZ immediately after they are created or modified. You can configure SRR using the S3 Management Console, API, or SDK.
SRR identifies objects for which you requested replication at the prefix, bucket, or tag level, and starts replication. You can set the AWS account that owns the original copy to own the replicated object. Alternatively, you can use a different account for the copies to protect them from accidental deletion.
Here are key use cases for SRR:
- Aggregate logs from several S3 buckets to process in the same AR. You can also use it to configure live replication between development and test environments.
- Make a copy of your S3 objects and keep it in the same AR to satisfy data compliance and sovereignty requirements.
SRR Use Cases
Here are key use cases for SRR:
- Aggregate logs into a single bucket—in some cases, you may need to store logs in several buckets or across different accounts. SRR lets you easily replicate these logs into one bucket located in one AR. You can then process logs in one location.
- Replication between developer and test accounts—sometimes, you may need to share data between test and developer accounts. SRR lets you use rules to replicate objects and metadata between multiple accounts.
- Abide by data sovereignty laws—some laws require storing data in separate AWS accounts and prohibit moving the data from a specific AR. SRR lets you backup critical data even when compliance requirements do not allow moving the data across ARs.
Related content: Read our guide to S3 buckets
How to Set Up AWS S3 Replication
You can set up S3 replication from one bucket to another by adding a replication rule to your source bucket. Here is a quick step-by-step tutorial on how to set up this kind of replication:
1. Go to the AWS S3 management console, sign in to your account, and select the name of the source bucket.
2. Go to the Management tab in the menu, and choose the Replication option. Next, choose Add rule.

Image Source: AWS
3. Under the Set resource configuration, choose the Entire bucket option. Note that when replicating buckets encrypted with AWS Key Management Service (KMS), this stage also requires choosing the correct key.
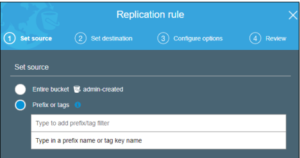

Image Source: AWS
4. Under the Set destination configuration, choose the Buckets in this account option. If you wish to replicate to another account, select this option and specify a bucket policy for the destination.
5. To change the storage class of the object after replication, go to the Destination options configuration, and select a different storage class for the destination objects.
6. You can also set the replication time. Go to Replication time control settings, and select the Replication time control option. This configuration provides you with 99.99% assurance that the system will replicate new objects within 15 minutes. However, this service level agreement (SLA) incurs additional costs.
7. Step 3—Configure options—lets you create a new AWS identity and access management (IAM) rule. However, if you already have an existing role with replication permissions, you can use it instead of creating a new one.
8. Go to the Status configuration and choose Enabled. To create the rule, choose Next. The replication should now start working. To verify this, you can wait several minutes and then check the destination bucket.
Limitations of AWS S3 Replication using Replication Rule
Here are key limitations of replication rules:
- Difficult to set up for sources outside S3—it is relatively easy to set up S3 replication for S3 sources. However, configuring replication to source outside S3—inside AWS or in another cloud—may require writing custom modules.
- Limited ability to apply transformation—enterprises often require applying transformation before replicating a date.
- Non-transparent pricing—it can be difficult to understand how Replication time control is priced and implemented, and this may result in operational overhead.
S3-Compatible Storage On-Premises with Cloudian
Cloudian® HyperStore® is a massive-capacity object storage device that is fully compatible with Amazon S3. It can store up to 1.5 Petabytes in a 4U Chassis device, allowing you to store up to 18 Petabytes in a single data center rack. HyperStore comes with fully redundant power and cooling, and performance features including 1.92TB SSD drives for metadata, and 10Gb Ethernet ports for fast data transfer.
HyperStore is an object storage solution you can plug in and start using with no complex deployment. It also offers advanced data protection features, supporting use cases like compliance, healthcare data storage, disaster recovery, ransomware protection and data lifecycle management.
Learn more about Cloudian® HyperStore®.